Evaluating the speed of GeForce RTX 40-Series GPUs using NVIDIA’s TensorRT-LLM tool for benchmarking GPU inference performance.
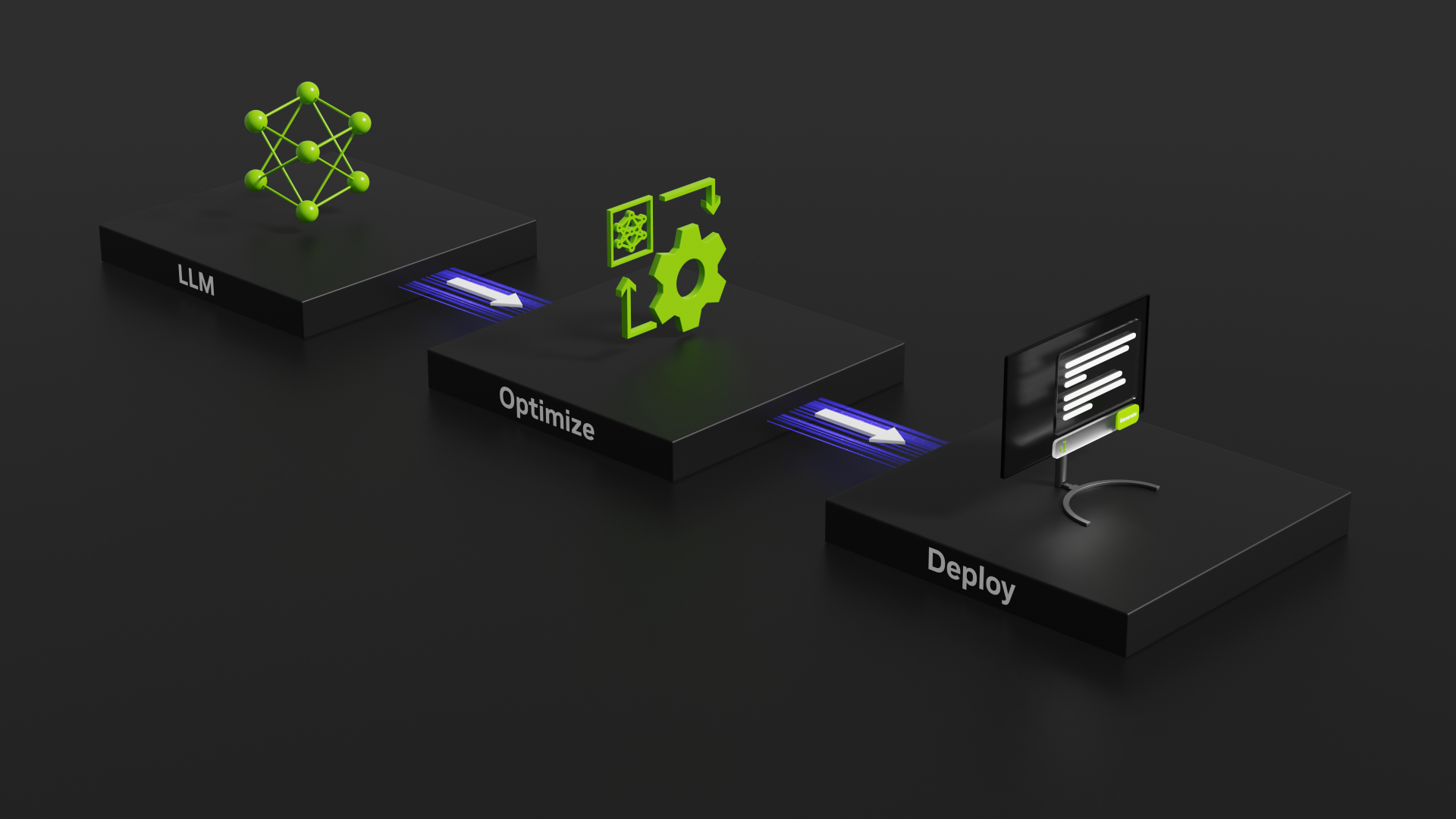
Evaluating the speed of GeForce RTX 40-Series GPUs using NVIDIA’s TensorRT-LLM tool for benchmarking GPU inference performance.
We have a new collection of GPU accelerated Molecular Dynamics benchmark packages put together for GROMACS, NAMD 2, and NAMD 3-alpha10. (The benchmark packages will be available to the public soon.) In this post we present results for,
– 3 applications: GROMACS, NAND 2 and NAMD 3alpha10,
– 8 MD simulations,
– 12 different NVIDIA GPUs,
– 96 total results.
In this post I will be compiling NAMD from source for good performance on modern GPU accelerated Workstation hardware. Doing a custom NAMD build from source code gives a moderate but significant boost in performance. This can be important considering that large simulations over many time-steps can run for days or weeks. I wanted to do some custom NAMD builds to ensure that that modern Workstation hardware was being well utilized. I include some results for the STMV benchmark showing the custom build performance boost. I’ve included some results using NVIDIA 1080Ti and Titan V GPU’s as well as an “experimental” build using an Ubuntu 18.04 base.
One of the questions I get asked frequently is “how much difference does PCIe X16 vs PCIe X8 really make?” Well, I got some testing done using 4 Titan V GPU’s in a machine that will do 4 X16 cards. I ran several jobs with TensorFlow with the GPU’s at both X16 and X8. Read on to see how it went.
I attended the Microsoft Build 2018 developers conference this week and really enjoyed it. I wanted to share my “big picture” feelings about it and some of the things that stood out to me. I’m not going to give you a “reporters” view or repeat press-release items. This is just my personal impression of the conference.
I have been qualifying a 4 GPU workstation for Machine Learning and HPC use. The last confirmation testing I wanted to do was running it with TensorFlow benchmarks on 4 NVIDIA Titan V GPU’s. I have that systems up and running and the multi-GPU scaling looks very good.
Batch size is an important hyper-parameter for Deep Learning model training. When using GPU accelerated frameworks for your models the amount of memory available on the GPU is a limiting factor. In this post I look at the effect of setting the batch size for a few CNN’s running with TensorFlow on 1080Ti and Titan V with 12GB memory, and GV100 with 32GB memory.
Tensor-cores are one of the compelling new features of the NVIDIA Volta architecture. In this post I discuss the some thought on mixed precision and FP16 related to Tensor-cores. I have some performance results for large convolution neural network training that makes a good argument for trying to use them. Performance looks very good.
NVIDIA’s Graphics Technology Conference (GTC) is probably my all-time favorite conference. It’s an interesting blend of “Scientific Research meeting” and Trade-Show. It’s put on by a hardware vendor but still feels like a scientific meeting. It’s not just a “Kool-Aid” fest! In this post I go present some of my thoughts about this years conference.
This post will look at the molecular dynamics program, NAMD. NAMD has good GPU acceleration but is heavily dependent on CPU performance as well. It achieves best performance when there is a proper balance between CPU and GPU. The system under test has 2 Xeon 8180 28-core CPU’s. That’s the current top of the line Intel processor. We’ll see how many GPU’s we can add to those Xeon 8180 CPU’s to get optimal CPU/GPU compute balance with NAMD.
Puget Systems builds custom workstations, servers and storage solutions tailored for your work.
We provide:
Extensive performance testing
making you more productive and giving better value for your money
Reliable computers
with fewer crashes means more time working & less time waiting
Support that understands
your complex workflows and can get you back up & running ASAP
A proven track record
as shown by our case studies and customer testimonials
